
Serposcope 3の使い方覚書です。
(2025年追記)Serposcope 3が使えなくなった件を追記しました。
前々から知っていたのですが、使ったことなかったので使ってみました。昔はGRCの月額版を使っていたのですが、最近はあまり検索順位を見なくなったので切り替えました。
実際に導入してみてわかったのは、かなり遅いです。もしも導入する方は先に「遅い理由」の項目をみるとよいでしょう。
Grcで10分でできることが、serposcopeでは100分ぐらいかかります。serposcopeもお金をかければ改善できる気もしますね。
Contents
2025年!serposcope 3が使えなくなった。
久々にserposcope 3をテストしたところ、使えなくなっていました。。
アップデートはかけてみましたが、ダメでした。
エラーをおうと同じような事例がありましたね。
I am seeing this error now, All proxies or checkers failed. Searches left: 4. Last error: "Got a captcha but no solver available" (check Settings > Logs for all errors).
— Jimmi (@jimmiprajapati) January 18, 2025
フォーラムでも同じような人がいましたね。開発者さまは時間がなく数ヵ月の時間をとるだろうと言われています。
I don’t have the time to fix it now. It will take a few months before I work on Serposcope again.
The small 3.5 fix I made works if you don’t use num=100 and use captcha solvers.
https://forum.serposcope.com/d/223-error-not-working-at-all/
Googleに見事に対策されましたね。
captcha solversの利用を促していますね。CAPTCHA ソルバーとプロキシの設定にはお金がかかります。
serposcope派の人は、なるべく早くCAPTCHAサービスhttps://anti-captcha.com/とVPSサーバーを申し込みましょう。プロキシもです。

ただ、個人的にはそこまでやるのは正直めんどくさく感じます。それにお金がかかるため、他の有料ツールを使った方が安価にすみます。このかたも同じようなことを言われています。
I tried the same scraping settings, but couldn’t get a good measurement.
Probably the number of proxies and captcha measures are insufficient.
Rather than spending money on so many proxies and captcha measures, it would probably be cheaper to use a paid tool.
https://forum.serposcope.com/d/243-i-have-not-been-able-to-get-search-rankings-since-march-20-2025/14
(中略)
Yeah ive got a deal on the 100 proxies, so its workign ok atm. but once the deal finishes i wont be using it any more.
(追記)作者さまは忙しいようで取り組むことがないと明言されています。
Unfortunately it's very unlikely I work on Serposcope soon.
— Pierre Noguès (@serphacker) January 25, 2025
GRCなど他のツールも動かなくなっているようですが、解決策をみつけました。詳細はこちらです。
serposcope バージョン3のダウンロード・インストール
公式サイトに移動します。
Download > Just download
serposcopeのインストールは迷うところはありませんでしたが、Javaがインストールされていない場合は事前にインストールが必要です。
serposcopeは最初にsettingをすることをおすすめします。
そのあと、プロジェクトの追加、Webサイトの追加、キーワードを追加の順番です。
serposcope 3はJavaが必要?Javaをインストール!
Javaがインストールされていない場合はインストールします。
Javaのインストールの詳細はこちらです。

serposcope 3のアップデート
アップデート方法も記載しておきます。画面左下に現在のバージョンが表示されます。
[UPDATE AVAILABLE]のボタンをおします。新バージョンがでていたらダウンロードします。
[Support Forum]で問題が起こっていないかも確認しましょう。
serposcope 3の起動
Windowsの場合はスタートアップに登録されます。ショートカットもデスクトップにできます。
macの場合はserposcope.urlというものがデスクトップにできます。ターミナルから操作もできます。
serposcope 3のsetting
settingを行わないとデフォルト値が変わりません。個別に毎回設定する必要がありそうです。
たとえば、日本語に設定していないと、キーワードを追加するたびに英語から日本語に切り替える必要があって面倒です。なお、言語設定はUIを日本語化するわけではありません。検索対象を日本とするだけです。
- Default seach language:ja(Japanese)
- Default seach country:Japan
- Cron status:検索順位チェックを自動化するか否かのチェックボックス。チェックを外せば定期チェックは行わないはず。
- Cron time:自動取得の時間(PCが起動していないとNG)
- SERP history:おそらく検索順位の履歴を何日分保存するかを指定のようです。デフォルトでは365日になっています。キーワードが1000超える場合は、もっと値を小さくしましょうとアドバイスされています。
serposcope 3のプロジェクト
どうやらプロジェクトごとにキーワードが管理されるようです。
同じキーワードを狙ったサイトがある場合、1プロジェクトに複数サイトをいれるとよいです。
serposcope 3でWebサイトの追加
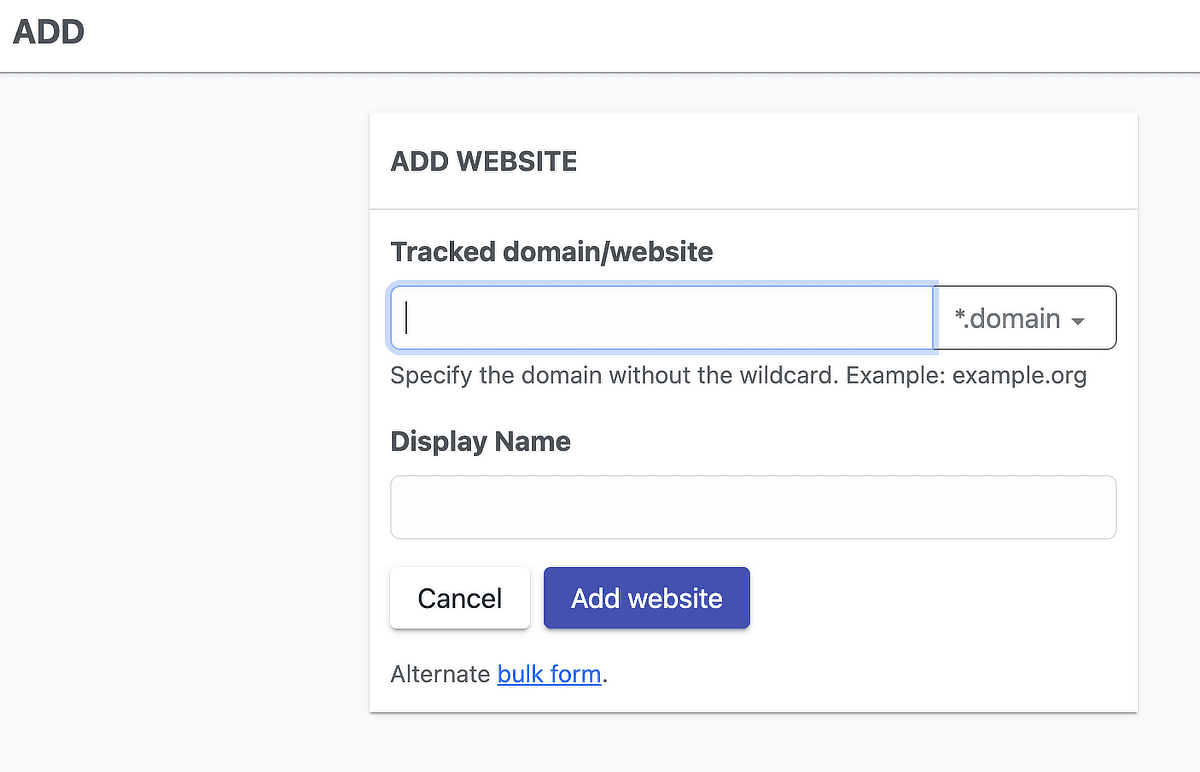
- *.domain – サブドメインを含むドメイン全体を追跡
- domain match exact domain – 入力されたドメインのみを厳密に追跡
- URL match the exact URL – 入力されたURLと完全に一致するページのみを追跡
- Regex match a custom regex (expert) – 正規表現でカスタムのパターンにマッチするURLを追跡
recommendedと書かれていたこともあり、1番上を選びました。
https://www.ithands.dev/と入れるとエラーがでます。
Failure{id='saas.core.impl.com mon.Domain.InvalidDomainNa me', path="/}この場合、httpsはいりません。ithands.devです。
serposcope 3でWebサイトの削除
Rank Tracker > 削除するWebサイトを選択 > Settings > Delete website > Confirmer
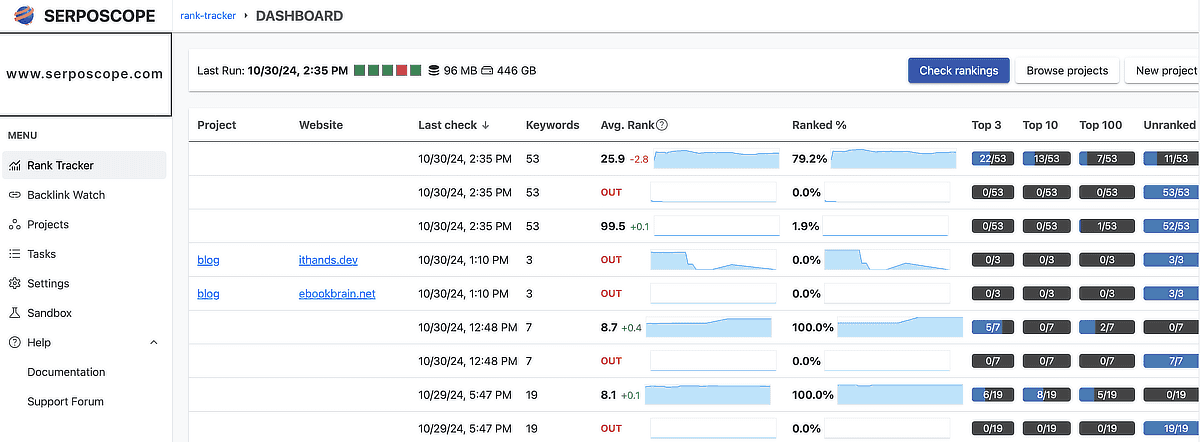
serposcope 3の定期チェック
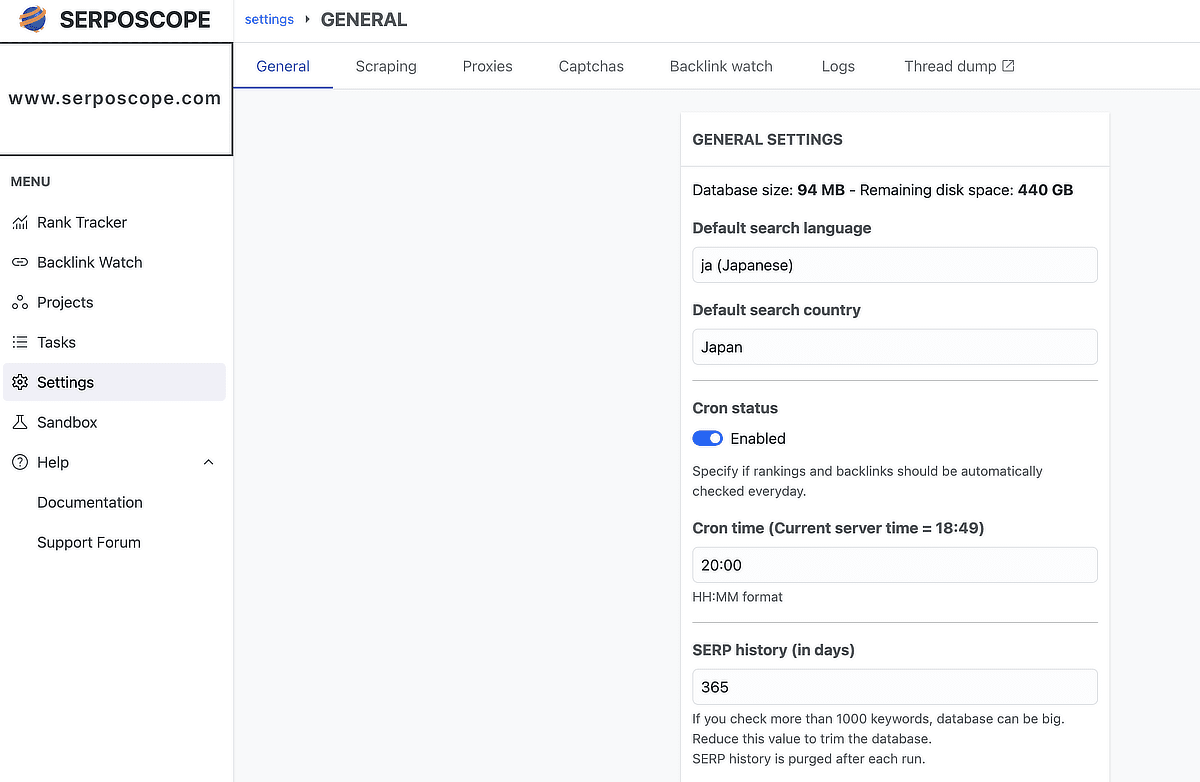
Serposcopeをローカルにインストールした場合は、PCはもちろんブラウザも起動していないとチェックされないようです。もしもそれが嫌ならVPSサーバーの導入がおすすめです。
定期チェックの期間はキーワードを追加するとき以外にも、一括で変更できるようです。
Manage Keywords > チェックボックスで選択 > Selection > Edit Check interval
serposcope 3で検索チェックツールが遅い
遅い理由はデフォルトで検索順位を1位~100位までチェックしているからでしょう。かなり設定をいじる必要があります(エラーのところで後述した)
ただ、設定を変えてもGRCよりserposcope 3は遅いです。ソフトウェアの作りが違うから。
キーワード数が多い場合や遅いのが嫌ならGRCを使った方がよいです。とても快適です。
serposcope 3のデータ移行
WindowsからMacにデータ移行した覚書です。
serposcope 2まではsaveとrestoreがあったみたいですが、ぱっとみ、3では見当たりませんでした。
情報はほとんどなかったのですが、公式サイトを手掛かりに引越しできました。
Where is located the data directory ?
https://www.serposcope.com/en/docs/faq.html
Windows:C:\ProgramData\Serposcope
Linux:/usr/share/serposcope
Mac:/usr/local/serposcope
How to access database ?
Serposcope 3 is using sqlite3. You can access it using the sqlite binary.The database file is database.sqlite3.db and located in the data directory.
https://www.serposcope.com/en/docs/faq.html
この手順は新規環境に上書きする手順です。念の為ですがマージはできません。
1. WindowsのC:\ProgramData\Serposcopeにアクセスし、以下の3つのファイルをバックアップします。
database.sqlite3.db-waldatabase.sqlite3.dbdatabase.sqlite3.db-shm
database.sqlite3.dbがメインのファイルですが、これら3つのファイルは、SQLiteデータベースにおけるデータ整合性を保つために連携しているようなので一緒にコピーします。
2. Macの /usr/local/serposcope フォルダにある同名のファイルと置き換えます。上書きコピーします。
3. しかし、ブラウザを再読み込みにしても、それだけでは反映されませんでした。再起動したらデータがきていました。
4. けれど、次は検索順位のチェックをするとエラーが発生しました。

internal error: org.sqlite.SQLiteException: [SQLITE_READONLY] Attempt to write a readonly database (attempt to write a readonly database)このエラーは、SQLiteデータベースファイルが読み取り専用(read-only)になっており、Serposcopeがデータを書き込もうとしたときに発生します。
WindowsからMacに移行した際に、権限情報が適切に移行されない場合があり、たぶん書き込み専用になってしまったのでしょう。
# 現在のファイル権限を確認
ls -l database.sqlite3.db*
# 所有者とグループに書き込み権限を追加
sudo chmod 664 database.sqlite3.db
sudo chmod 664 database.sqlite3.db-shm
sudo chmod 664 database.sqlite3.db-wal5. 再度、再起動をかけたらうまくいきました。
serposcope 3のbacklink watch
serposcope 3ではバックリンクを監視できるようになったのですかね。
📢 Free self-hosted Serposcope 3 is available:
— Pierre Noguès (@serphacker) August 17, 2023
◆ Rank tracking
◆ Backlink monitoring
◆ And more SEO tools coming soon
Download it -> https://t.co/7fiMowkQFH pic.twitter.com/esd3yNVlYc
けど、少しだけ試したところ、ahrefsのような被リンクチェックツールとは違いました。残念ながら使えないですかね。もしかしたら勘違いしているだけかもしれませんので、気になる方は試してもいいかもです。
serposcope 3がエラーで使えない!動かない(遅い理由)
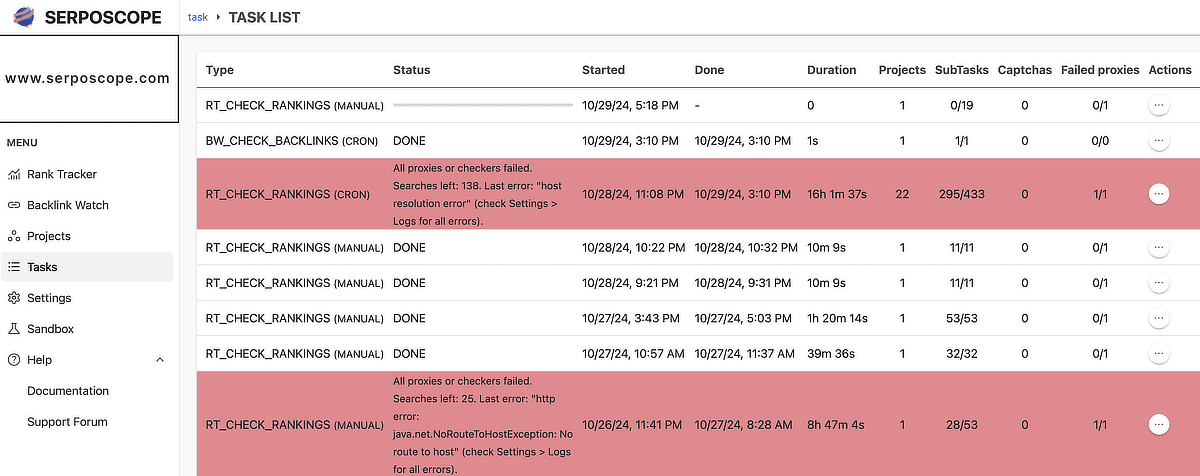
serposcope はとてもよくエラーがでます。
技術者としてひとつひとつ解決していく必要があります。技術者としてと書いたのは、プログラマ系の人じゃないとおそらく乗り越えられない気がしましたね。難易度が高くて。
楽をしたいのならGrcがおすすめです。
internal error: org.jsoup.helper.ValidationException: String must not be emptyこちらはjsoupのライブラリ関連のエラーのようです。プロキシの設定に関する見直しなどが必要そうです。
All proxies or checkers failed. Searches left: 23. Last error: "Got a captcha but no solver available" (check Settings > Logs for all errors).いろいろな回避方法が考えれそうですが、無料の回避策は検索間隔を長めに設定するぐらいです。
CAPTCHA ソルバーとプロキシの設定に費用がかかる!VPSサーバーの導入も
CAPTCHA ソルバーとプロキシの設定にはお金がかかります。両方が必要な気もします。海外のサービスに申し込んで支払いも必要なので、なかなか面倒です。VPSサーバーも借りないといけません。
それならGrcでいいのではないでしょうか。
無料のプロキシは使い物にならないので、有料のものが必要です。Googleに対応されていておしまいです。
時間の間隔をあければCAPTCHA(画像認証)を回避できそうです。Serposcope が Google 検索結果を取得する際に、アクセス頻度が高いと Google から CAPTCHA を求められることがあります。
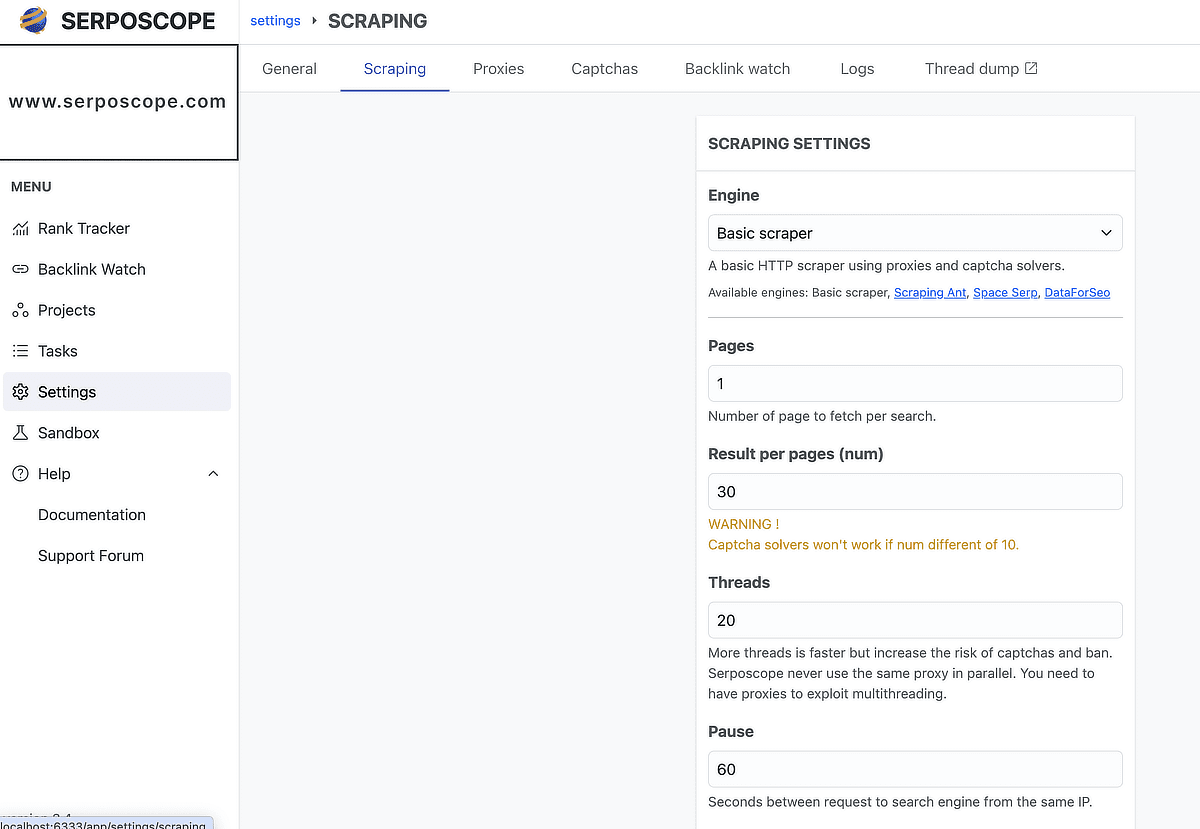
Setting > Scraping>Pause
デフォルトは10秒になっていましたが、10秒ではGoogleにはじかれてまともにチェックができません。30秒ぐらいにしたのですが、ぜんぜんダメでした。最低でも1分、できれば2分はあけたいです。しかし、2分にしたら10秒の12倍の時間がかかるわけです。
最初に言っておくと時間の間隔を広げればエラーが解決するという生易しいものではありません。Googleの対応などが変わればまたエラーがでます。状況によってエラーがでたりでなかったり。
デフォルトではページ数が10となっており、10ページ100位までチェックするようです。
Grcと違って全順位を取得する形なので遅いのですよね。
1つのキーワードに1分 * 10ページ = 10分かかってしまいます。
10個のキーワードで100分です。
100個で1000分(16時間40分)です。
これに耐えられないなら高速で快適なGrcです。
ページ数を5にしたら50位までのチェックで半分の時間ですみます。
500分です。
ページ数を3にしたら30位までのチェックです。
30位*100キーワード=300分。5時間です。パソコンをつけっぱなしの人は現実的かもしれませんね。
もう少しどうにかかならないのでしょうか。
1つのプロジェクトを50キーワードぐらいにしましょう。
30位*50キーワード=150分。2時間半です。
プロジェクトを分割して10個のプロジェクトを順番に回せばいいかもしれませんね。
本格的にSeoをやりたい人には向かないかもしれません。これに耐えられないなら高速で快適なGrcです。
500円、1000円ぐらいですごく快適に使えますよ。
serposcope 3とGRCと比較!個人的な結論はどっち!?
10日ほど運用したため、結論を加筆します。
結論をいうと、APTCHA ソルバーとプロキシの設定をがっちりとやらないと快適に使えそうにありません。逆にいうとGRC並みのお金をかけて、そっち方面の技術的な知見があるエンジニアなら快適に使えるでしょう。勉強が必要でやれば解決できるのでしょうけど、個人的には他の開発に忙しいので、しばらくGRCに戻ろうかと検討しています。
GRCがとてもよくできたソフトウェアと知っているのもあります。
serposcopeは少ないキーワードなら、APTCHA ソルバーとプロキシがなくてもなんとかチェックできるかもしれません。間隔も30秒ではダメですかね。2分以上あけます。
キーワードを増やすとエラーで止まってしまいます。
Result per pages (num)を増やすという作戦はありかもしれません。
- まず、前提としてプロジェクトあたりキーワードを30個程度にして極力、分割する。プロジェクト単位で調査できるから。
- Pause 120:デフォルトの10から120(2分)に変更し、画像認証の表示を回避。2分もあける理由はGにbot判定をうけないようにするため。
- Pages 1:デフォルトの10(100位)から1に。Pages*Result per pages (num)という掛け算なので、こちらを1にしても、Result per pages (num)を30にすれば30位まで取得できます。
- Result per pages (num):デフォルトの10から30に変更し、1回で全取得できるようにする。
これで2分に1回一括で30件まで取得するという意味になります。10キーワード20分です。100キーワード200分(3時間20分)です。ちょっと長いので1プロジェクトだけ手動チェックするなんて使い方がいいところかもしれません。
WARNING !
Captcha solvers won't work if num different of 10.
Result per pages (num)を30にすると、WARNING !が表示されますが、CAPTCHAソルバーサービスを使っていなければOKです。
誤魔化ながら使っていく必要があるので、serposcope派の人は、なるべく早くCAPTCHAサービスhttps://anti-captcha.com/とVPSサーバーを申し込みましょう。
こちらの契約をすれば時間的にも快適になるでしょう。
参考になれば幸いです。
コメント